IMDb Consumer - Modern API
IMDb Consumer - Modern API
In order to enable the Consumer IMDb org to move faster in delivering new and better features we plan to introduce a thin and centralized API. This API will be built to power all the Consumer clients (Web, Android, and iOS) and support clear ownership and development model. The following will describe our current problems and our strategy to address them, the technology we think best enables that, and the expected product we can use to prove it out. We seek feedback from management and product to validate that the approach produces an outcome worth the cost, is making the correct tradeoffs, and is setting us up for future success.
Tech Problem
The current generation of IMDb's consumer-facing surfaces include Web (mobile and desktop) and the native Android and iOS mobile apps. Each of these surfaces rely on a backend API to get the necessary data; for the mobile apps this is Zulu while the websites leverage their IMDbConsumerSite (ICS) and Horizonte (Hz) stacks. These services interact with Tango and other data sources to create data models that power the consumer user experience.
With this layout, when building a feature we draw a line from the Db (bottom) to a surface (top) and along that line have to write code in every box we touch. This is time consuming and results in duplicate and oddly distributed code, with much of it is written closer to the customer in our clients (the code that is our surfaces).
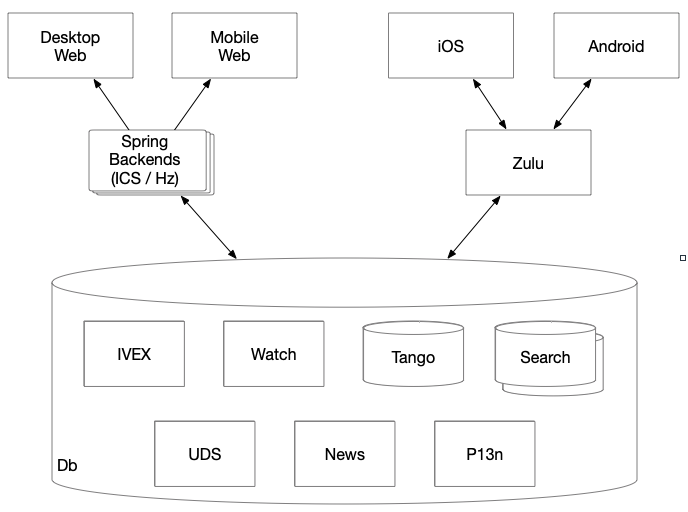
Duplication across the client code is to be expected when rendering an experience; the Web, Android, and iOS each have their own separate toolkits to write their "render logic". It is the duplicate and distributed nature of the "business logic" in the client and API code that is the hindrance and introduces a number of side effects including increased development velocity and ownership costs, data consistency issues, as well as latency and security concerns.
Business Logic
What is business logic? It is a fuzzy term that we use to cover all manners of debt in our code base, but for our purposes it is the code that builds data. For instance if I wanted to show how many writers worked on a film below the title text; I could get the title text and a list of all the writers, then count those writers. This is different than render logic which is the packaging of data (the text and number) for a particular widget (e.g. no counting).
Development Velocity and Ownership Cost
Using Hz, ICS, and Zulu to build out a feature across our clients is a high development effort. Within those services the data is read and processed for the client and is a mix of "business" and "render" logic. For Android and iOS there can be additional Zulu adjacent code written in our homegrown JSTL; this code is used to further process and batch that data for each app. When all is said and done there could be code changes in approximately 7 places (4 clients, 2 api layers, and 1 backend) when launching a new feature.
The act of writing more code means a lower development velocity, which is compounded by the order in which the teams need to execute (backend before API, API before client). This clearly impacts the time we can get a feature to our customers, even the well executed launch of News took 8 weeks to complete across all surfaces.
Once written, code incurs a maintenance cost on the owner. This cost shows up in a number of different ways such as bug and security fixes, slower future development velocity due to refactors, and a higher dependency on Subject Matter Experts (SMEs). For instance the launch of IMDb TV on mobile apps was negatively impacted when a caching bug was found on getting offers for non-logged in users; this took three L6 SDEs 2 days to determine what change should be made in the impacted code.
Data Consistency Issues
As of today, IMDb's operations team fields questions from a range of IMDb customers about incorrect data. Many times, this data is correct in Tango (a large chunk of our Db) but appears incorrect when viewed through a particular client. This is a direct result of critical business logic being placed close to the customer in client or API code (or both). When this code is duplicated or has ambiguous ownership, it can make it difficult to track down and fix in a timely fashion, but it always breaks trust. For example, the formatting of writers credits is specifically defined by the WGA (Writers Guild of America), thus in ICS and Zulu there is code to take the raw credits data and carefully display them according to that specification. This has been implemented incorrectly twice by Consumer facing teams when Content owns the relationship and corresponding policies with the WGA. While these particular issues were visible enough to be quickly fixed, it is a trustbuster for both our customers and stakeholders.
Latency and Security
IMDb's US consumers see mostly acceptable above the fold latencies when accessing data using ICS and Zulu. The further away the customer, the more the performance degrades, with those in India seeing latencies of between 20 and 60 percent slower than the approximately 3 seconds US customers wait to see content on the homepage.
The performance seen today is achieved using different means of caching between ICS and Zulu. In short, ICS caches what it returns (the page) while Zulu caches what it reads (the data), thus each have different characteristics, levels of configurability, and resilience. The complication in this space and the related performance issues introduce friction with the user; if the data is slow or the site browns out those users will find another source of data.
Less critical at the moment is how we secure our's and our customers' data. In addition to variance in caching, there have been different security models in place to protect the data. While they have begun to converge, we are still requiring multiple publicly facing data sources (our web stacks and Zulu) to ensure that bots and malefactors do not steal our data or interrupt our service.
Tech Strategy
To resolve these problems we need to reduce code duplication by limiting the number of places that we have to write the our logic and aggregation from many to one. In the process we need to also define better ownership of the "render" and "business" logic.
This means we change our architecture from several fat APIs (Zulu, ICS, Hz) to a single thin API. It is "thin" because all of its code is infrastructural, making aggregation, scaling, and operations its chief concern. This provides the clients unified access to the backend teams/services, and it is those backend services that should now be responsible for the "business logic" that falls under the charter of their team, freeing the client teams to focus on the "render logic". This will address the _Ownership Cos_t and _Data Consistency Issues _described above by having less distributed code.
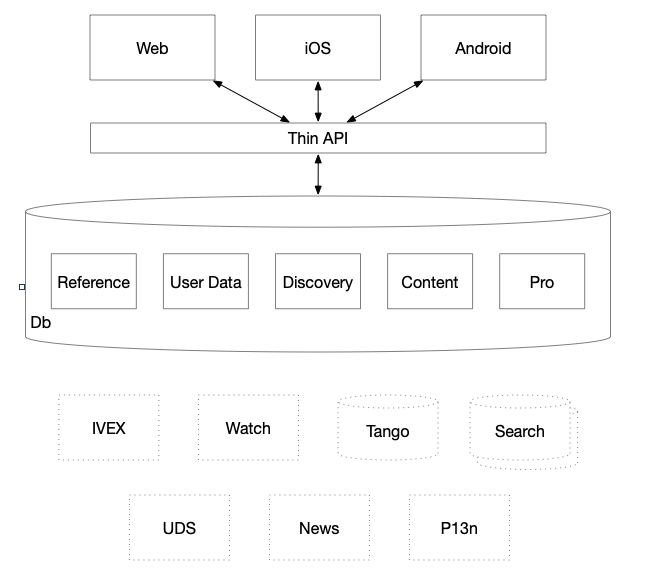
This means that a new feature would need changes in the frontends, each building the different layout functionalities, and potentially changes in the backend services to expose more data fields, but would not need any changes in the thin API layer. The only time that work would have to be done on the API layer would be infrastructure improvements (e.g. scaling and operations) and the one-time cost onboarding each new backend service. This new pattern should improve Development Velocity and help centralize Latency and Security.
Practically, this means that to launch a new feature, instead of having to change the code in the approximately seven different places (desktop/mobile/iOS/Android/Zulu/ICS/Backend), we would only have to change four (web/iOS/Android/Backend). Note, this assumes we reduce the web client to a single stack, but that is outside the scope of this doc. See IMDbNext: A Proposal for a Consolidated Front-End Architecture for details on that approach.
Once this system is up and running, the API team will own the observability of the API and its interactions. They will have metrics around the speed of each query and each field resolution, and will be able to determine what is slowing down the graph, and who to talk to to improve it. They could go to front-end teams to tell them that they just launched an extremely slow query, or a back-end team to tell them that a certain field they serve just got slower. While the changes described above should bring about more near-term improvements, this functionality will enable continuous improvement in all problem areas we see today.
GraphQL
In order to execute that strategy (less code, clear ownership) we have looked into doubling down on REST either via a centralized service (e.g. Zulu) or via a proxy (e.g. Device Proxy). These are tried-and-true but bring enough known baggage that we are not confident that we would be able to solve the overall speed of development problem (See Appendix 2 for details). We instead will pursue using Federated GraphQL as the thin API for all clients, as GraphQL is a well supported technology that is proving itself useful both inside (Twitch) and outside (GitHub, Facebook) Amazon.
Why use it?
GraphQL is a framework that allows developers to start with a schema for reading and writing data that can then be efficiently populated writing pieces of code called resolvers. The clever part is that from the client's point of view, they simply describe which pieces of data they need from the schema, the service will then provide that data by executing only the applicable resolvers. This allows for aggregation of data from multiple services without those services taking deep dependencies on each other; this behaves much like our use of JSTL to aggregate data across several APIs. (See Appendix 1 for more detailed description and examples)
We believe that this schema-first style of building and using an API is a good fit as our thin API because it simplifies what clients can do (data selection) and places the burden of the business logic in the backend as the resolvers. GraphQL also has a very active developer community that has produced plenty of documented samples, discussion, and open source tooling which makes adoptions easier.
How it fits?
Using vanilla GraphQL, this would mean that the GraphQL adaptor logic would live in the main API, thus either the API team writes the schema and resolvers or the backend teams would do away team work in the API's codebase. Similar approaches have been tried with Zulu and ICS, resulting in our classic monolith problems, where we implement processes to slow down and reduce blast radius (e.g. many pipelines) or we suffer the throughput of a single team's backlog. In both cases it is not a thin API.
This means that the technology requires some adjustments to prevent the bottlenecks we've seen in ICS and Zulu. The company Apollo GraphQL has a specification and open source implementation that enable a single gateway to compose contributions from multiple federated services into a single graph. This works by introducing a new @key directive (the GraphQL version of an annotation) into the schema that turns a type into an entity. Any entity can then be extended by any of the federated services, so long as they use the same @key to identify it. Practically this means that Reference could provide the core video data (text, image, token) while User Data could add on an "isInList" attribute to that video data without needing Reference to make any changes.
By using Federated GraphQL we can prevent the API layer from becoming a monolith of code and let it focus on more general concerns, but this implies that the backends must be GraphQL services to be members of the federation. This introduces a new tech stack that those teams need to adopt, but allows them to choose the implementation and their deployment schedule. Put into real terms this means that if a new feature needs team A to add some data to the graph only the deployment of A's service should be required to add that data.
Internally there is AmazonGQL which bolts onto ARest, Coral, and Horizonte to create a non-federated Java based /graphql endpoint. It is also fairly straightforward to use Apollo GraphQL to host a service in Lambda behind API Gateway. These options are available to the backend teams and should reduce the burden to implement the federation specification in order to participate in the graph. While they do not solve all of our problems out of the box, part of the problem is already solved for us.
Initial Deliverable
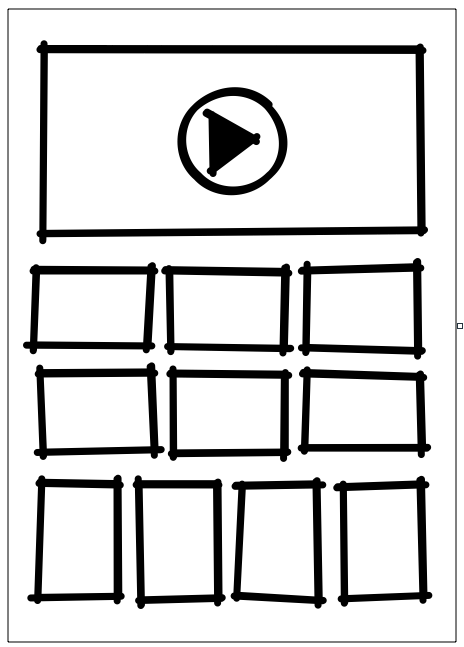
In an effort to increase video viewership on IMDb via discovery, there are plans to introduce a new Video Collection Page (VCP). The first use case for this page would be to replace the IMDb TV landing page, deprecating an existing web stack. It will provide a list of videos to play, with the addition of an inline playable hero at the top. The IMDb TV content would behave exactly like it does today (Poster, Title, Date, Title Page Link, and Add to Watchlist). The data to power the page will come from the User Data (UDS, Watchlist), Consumer Reference (Video), and Stingray (Title/Name) teams.
We believe that this product provides the opportunity to provide value to our customers and address our duplication issues in such a way that we can deliver more functionality cheaper and faster going forward. This page also lets us launch without integrating inline advertising, as ads are part of the video experience itself.
Milestones
The below is what we believe to be an achievable set of deliverables that could lead to functionality delivered in Q1 2020, with more (e.g. Lite App) to follow rapidly in Q2:
- Product has defined the UX, front end has determined the schemas in partnership with back end teams
- API team has a federated gateway to nowhere with stub data, continuously deployed to one region
- API team has a basic schemas package set up to allow federation to begin
- Web team has a website to display that stub data, continuously deployed to one region
- API team's gateway has basic observability (client validation, request tracing, query and field level metrics, alarming)
- API team's gateway performs field-level caching
- User Data and API teams integrate UDS into the graph to convert cookies into user IDs
- Reference integration of Video endpoint and schema
- Stingray integration of reference data endpoint and schema
- User Data integration of Oskar list endpoints and schema
- Web team populates page with non-stub data
- API team has a way to onboard schema changes to the graph in an automated fashion (with manual approval)
- Feature complete across all front end and back end teams
- 10% launch weblab of Video Collections Page with a Beta tag
- Schemas defined for second TBD page (Title Goofs, to deprecate another stack?)
- 100% launch of Video Collections Page
- Already started development on the front end site and back end integrations for the second TBD use case
Conclusion
We believe that Federated GraphQL as the "thin API" with the functionality described above will enable increased development velocity. With this architecture the clients can define their data needs and the backends can take ownership of fulfilling them in the most optimal way, allowing for horizontal scaling of development without unnecessary bottlenecks.
We also believe that leveraging a new feature like the Video Collection Page provides an opportunity to establish this new service and development model which can quickly give way to other initiatives like the International Lite App.
FAQ
1 - How do new features get built (e.g. Who do I talk to)?
Hopefully its as simple as working back from the customer. Assuming we are in a steady state where clients and backend services are onboarded to the Thin API, then a typical flow for feature development would look like the following:
- Product defines a new feature
- UX defines wires, not redlines, enough to unblock clients
- Client team(s) work with Product and UX to determine the necessary data and then identifies the appropriate backend service owners
- Client works with Backend service owners to define schema updates for any missing data (skip if the data is already in the graph)
- Backend owners update schema, providing placeholder data if necessary (skip if the data is already in the graph)
- In Parallel
- Redlines are defined and refined
- Client teams develop UX against schema
- Backend teams develop data providers (skip if the data is already in the graph)
Ultimately it is achieving this flow that would be the big win with this technology as it would be fast distributed development with clear ownership, uniform access, and no unnecessary process blocking development/deployment. Product would not need to interact with more teams than they do today; instead of having to schedule work across client teams, API, and backend teams, they would only have to schedule work across client teams and the backend teams.
2 - How do we ensure no unintended side effects (e.g. Client query changes browns out a backend)?
A critical piece of the Thin API must be that it provides observability. This means that it should produce both realtime and over time reporting that includes details such as
- What are the top N queries
- Who is performing them
- Is their cacheability optimizable
- What fields are most used
- What are the top slowest fields
- How is the load on the federated services distributed
This means that the API team should be in a position to make recommendation to both client teams to optimize queries for cacheability and backend teams to pre-compute the most important data. This same data should also enable analysis of updates to make safer deployments and releases.
3- What are the risks and one way doors to this new strategy?
Federation: Scale
The largest risk is that there is no team at Amazon running a Federated GraphQL instance at the scale that we are planning to. Twitch is running GraphQL, but not Federated, at a scale similar to ours.
Federation: Query Ownership
With a Federated system and no API team bottleneck, we introduce the possibility of two teams writing conflicting queries, causing business logic to bubble up to the frontend. For example, Reference could write a heroVideo query, and then Pro would want a proHeroOverride query. Now, we've pushed decision logic to the frontend; it would have to know to call both and which one to choose over the other. With a gatekeeper, we could have pushed back, telling Reference they have to incorporate Pro's logic. The cost of each one of these mistakes is small; a team writes a query or populates a field that is not what is needed, and has to be absorbed into another one. However, if we make this mistake frequently, it will impact overall velocity.
Federation: A Two Way Door
Federation is not immediately a one-way door, however, as long as the resolvers in the federated services are all written in the same language, a migration absorbing them all into a monolith would be a possibility. The longer we run on a Federated instance, the more work it would be to collapse back into a single service, however.
Cost
We are unsure on the cost of this system. While AWS keeps getting cheaper, and our internal discounts keep getting steeper, it is possible that we would build a system much more expensive than Zulu. Zulu costs ~$65K a month (and rising) to operate. However, this would be an issue migrating to any Native AWS system; an issue that teams across all of Amazon are facing as we all migrate to Native. The exact deployment mechanism of the Gateway could be swapped out anytime in the first year at a relatively low cost; for example, if the API team chooses Lambda at first, and we realize that it is much too expensive, we can switch to deploying on ECS instead.
A Single Point of Failure
The API will be a new single point of failure, since it will be handling every single traffic request from all IMDb apps and websites. This comes with some risks, the primary of which is the scale of the API itself. All of the Native AWS hosting solutions we will land on come with autoscaling, so the service itself should be horizontally scalable to any degree necessary, however the services behind it will not be. Additionally, we are building a system which will naturally attract every trouble ticket for every front-end issue, making the owning team potentially becoming drowned in ticket dispatch.
Both of these issues have solutions, but they will just require additional effort. We will need to think through and implement throttling mechanisms that make sense for the graph, the exact nature of which will not be as obvious until we spend some time operating the graph at a smaller scale. We will have to come up with a mechanism for tickets to go to the correct team; we could add @CTI directives to fields to allow for tickets to go directly to the correct team, or even a quicklink system for reporting issues to the correct team from a centralized UI.
Appendix
1 - GraphQL and Federation
What is it?
GraphQL describes itself as a "query language for your API"; with the following sales pitch found on the projects website:
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
What does that mean? For the purposes of this doc, assume the much oversimplified schema on the right. It describes a "name" and "title" that can be queried by an "id". This is our "complete and understandable description of the data"; two objects with some strings.
The client can then produce a query to get access to the data that they "need". For instance the query for a name object with only the birthplace
{ name(id: "nm1234567") { birthPlace }}
would only return something like
{ "data" :
{ "name": { "birthPlace": "SC" }}
}
This can even be more complex by reaching into child fields for particular bits of data like this like the birthplace of cast members of a title.
{ title(id: "tt1234567") {
cast(order: APPEARANCE,
limit: 10,
offset: 0) {
birthPlace
}
}}
"A rose by any other name..."
type Name {
id: ID!
name: String!
birthPlace: String
}
"Add me to your watch list"
type Title {
id: ID!
title: String!
plot: String
# This field takes arguments
cast(order: CastOrder!,
limit: Int!,
token: String): [Name]
}
enum CastOrder {
APPEARANCE
ALPHABETICAL
}
# Top level entry point for clients
type Query {
title(id: ID!): Title
name(id: ID!): Name
}
This kind of schema is powerful on the client, providing documentation and obvious query-to-data mapping; it even enables tools like autocomplete. It also provides the scaffolding for the backend to implement "resolvers" that populate the fields in an efficient fashion using several different language specific implementations (e.g. Java, TypeScript, Ruby, Go, etc...).
It's worth calling out what GraphQL is NOT. It is neither a graph database nor is it SQL/JSTL. It does not provide functionality like traversal of records and you cannot write logic in the client queries to produce analytical or massaged results. Unlike JSTL, you cannot perform operations like sorting or aggregate counting in the query itself; all of those operations must be sent as query parameters and performed on the backend instead. It is also not a silver bullet to solve all your API and data modeling issues; you cannot paper over poor or non-performant API design by bolting GraphQL on top of it.
Federation
The company Apollo GraphQL has a specification and open source implementation that enable a single gateway to compose contributions from multiple federated services into a single graph. This works by introducing a new @key directive (the GraphQL version of an annotation) into the schema that turns a type into an entity. Any entity can then be extended by any of the federated services, so long as they use the same @key to identify it.

Assume we start with a simple title type like this that is produced by GQL 1 in our picture:
type Title {
id: ID!
title: String!
}
Using the federation specification we can turn it into an entity by marking the id as the @key
type Title @key(fields: "id") {
id: ID!
title: String!
}
Now some other service, like GQL 3, could add an isOnWatchlist value by using the extend keyword and @external directive.
extend Title @key(fields: "id") {
id: ID! @external
isOnWatchlist(userId: String): Boolean
}
Now to all the clients that interact with the GQL - Gateway, they would see a schema that looked like the following as it would have blended the contributions from GQL 1 and 3 and now manages calls to them.
type Title {
id: ID!
title: String!
isOnWatchlist(userId: String): Boolean
}
Additionally these entities can also be referenced or included in other services. For instance GQL 2 could be a "list service" that only knows the IDs of an item to do the following
# Declared so the local schema is consistent and mergable in the gateway
extend Title @key(fields: "id") {
id: ID! @external
}
type List {
id: ID!
titles: [Title] # Uses Title just as if this service had defined it
}
Which would now allow for the query/data seen below, which returns an array of objects that contain the isOnWatchlist value for a given user for the first three titles in a list.
{
list(id: "ls1234567") {
titles(limit: 3) {
isOnWatchlist(userId: "ur1000000")
}
}
}
{ "data" : { "list": { "titles": [
{ "isOnWatchlist": false},
{ "isOnWatchlist": true},
{ "isOnWatchlist": true}
]}}}
This worked because when given the query the gateway had the mappings in place to get the initial list of titles from GQL 2 which would return that list with title objects that only had the id in them, and then use those id to call GQL 3 to get the isOnWatchlist data. All this data would be joined together and returned to the caller as the single result.
2 - Alternatives
While we do not have to go forward with this path, our other 2020 plans do not come for free. We will have to make a major investment in current systems, or a similar investment in alternative new systems, in order to power the features and initiatives we want to in the coming years. The two main possibilities if we do not go with GraphQL are "stick with Zulu" and "stick with REST".
Zulu
We could continue to launch features by adding new APIs to Zulu, instead of building a new API. Consumer Web engineers could learn JSTL and use it the same way the application developers do. However, this approach comes with several drawbacks, and is not as "free" as it might appear at first.
First, Zulu is already starting to hit some scaling limits, causing stability issues. It is completely cache dependent and CPU bound, and has a very large blast radius when it has cache problems, causing issues for every Zulu caller along with the other callers of the services it depends on (Tango, most prominently). We could mitigate this issue by continuing to partition Zulu into fleets for certain uses (Mobile, Web, Backend), but that does not help with the dependency problems, as any individual Zulu partition would still be able to generate enough traffic to brown out other services if the cache fails.
Second, JSTL has some flaws in both design and usability. If we are to become a site with a modern front-end using modern community tools, JSTL is a step backwards, since it is specific to IMDb, with syntax unlike anything else an engineer would use. JSTL has some tooling and observability gaps which would need to be addressed before adding more use cases. For example, there is no way of knowing the backend cost of a specific JSTL template call in production (we can tell the latency of a template if we search for it, but not why it's slow), so sudden increases in latency or CPU are unexpected and untraceable.
Third, Zulu is a monolith much like IMDbConsumerSite, containing a data and a presentation layer, all in one overstuffed Brazil package. The primary problem with this setup is that all of Zulu runs in a single JVM, so that any individual component can cause CPU/RAM/IO starvation on the entire rest of the service, even if that component is hidden behind ComponentEngine. Additionally, the package has hit some code scaling limits; for example you cannot run Fortify since it runs out of memory. We would need to break up the Brazil package into subpackages if it keeps growing. Zulu also is running on a single deployment infrastructure, with a single pipeline to Prod, making blockages more frequent.
The end result of these issues is that in order to continue using Zulu, we would have to do a major rearchitecting of it in order to power new use cases without compounding all of the current issues it has.
Device Proxy
We could execute a similar tech strategy; unified client access with strong backend ownership, without the use of GraphQL. This could be done by standing up a new publicly facing endpoint that doesn't host code, but rather routes to REST services owned by the backend teams. This proxy service would provide a single view of all the possible APIs that the clients can use and centralized the operational burdens. As it is a proxy, the work for new functionality is owned by the backend teams and thus would help keep the business logic out of the clients. This too has its drawbacks.
First, this plan requires building something new. Whether it is a customer service or managing integration with AWS's APIGateway there is still a body of work that needs to be done before others can onboard, and this puts it as no better than the GraphQL solution.
Second, a proxy solution does not provide the mechanism for clients to aggregate. This will either require the backend teams to implement aggregations outside of their domain or require the introduction of something like JSTL to remove the burden from the clients.
Ultimately this effort would violate our "build what's unique, import the rest" tenet without providing clear value.